Love the attitude 💪 Let me know if you need help in your quest.
I see.
So what do you think would help w/ this particular challenge? What kinds of tools/facilities would help counter that?
Off the top of my head, do you think
- The sign up process should be more rigorous?
- The first couple of posts/comments by new users should be verified by the mods?
- Mods should be notified of posts/comments w/ poor score?
I'm nitpicking but can you properly quote your code?
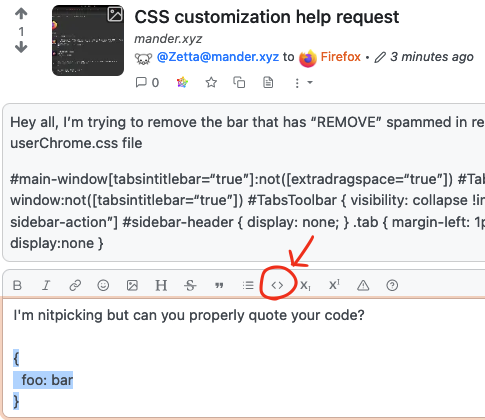
I just quote my comment on a similar post earlier 😅
A bit too long for my brain but nonetheless it is written in plain English, conveys the message very clearly and is definitely a very good read on the topic. Thanks for sharing.
Interesting topic - I've seen it surface up a few times recently.
I've never been a mod anywhere so I can't accurately think what workflows/tools a mod needs to be satisfied w/ their, well, mod'ing.
For the sake of my education at least, can you elaborate what do you consider decent moderation tools/workflows? What gaps do you see between that and Lemmy?
PS: I genuinely want to understand this topic better but your post doesn't provide any details. 😅
I'd personally appreciate if you explained the intention behind asking these questions.
Is this for your personal market-awareness? Or is it part of a survey (community or corporate?)
I just love the "Block User" feature. Immediate results w/ zero intervention by the mods 😆
Nice! Good to see this idea becoming more common 👍
I personally use Firefox Relay which gives me better control for my workflow - I usually need my temporary e-mails to last a bit longer, eg a week or a month.
On another note, the post clickable URL opens the Lemmy instace landing page and not that of the disposable email service.
A bit too long for my brain but nonetheless it written in plain English, conveys the message very clearly and is definitely a very good read. Thanks for sharing.
I had so many typos - typed that on my phone 🤦♂️ Glad I was able to communicate in some way 😂
That single line of Lisp is probably (defmacro generate-compiler (...) ...) which GCC folks call every time they decide to implement a new compiler 😆
To be fair, here's the complete paragraph which makes sense:
Vagrant public networks are less private than private networks, and the exact meaning actually varies from provider to provider, hence the ambiguous definition. The idea is that while private networks should never allow the general public access to your machine, public networks can.
21
cross-posted from: https://lemmy.ml/post/4440129
I am not the author.
https://addons.mozilla.org/en-GB/android/addon/github-license-observer/
https://github.com/galdor/github-license-observer
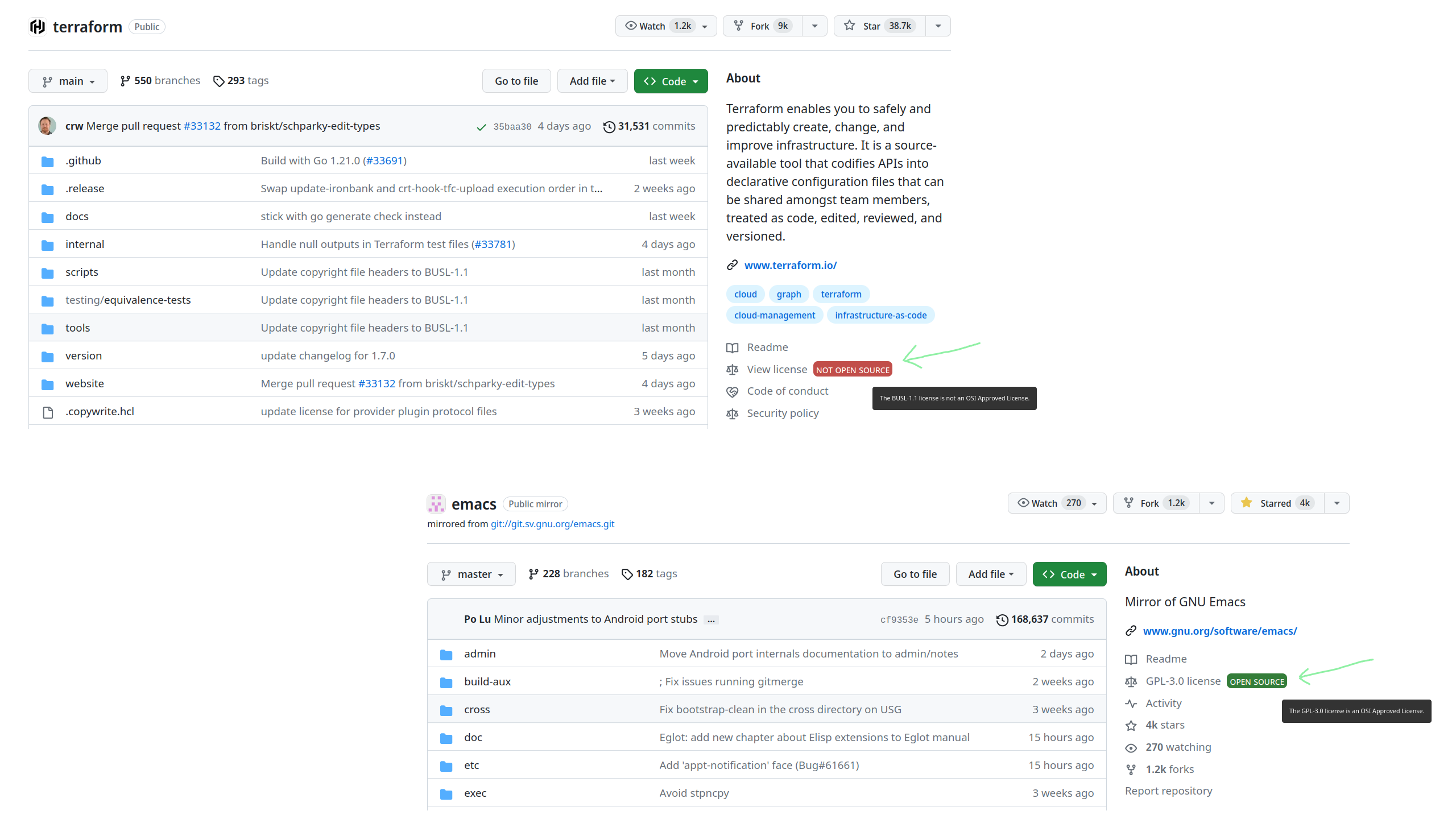
This is a cool little addon to help you tell, at a glance, if the repository you're browsing on github has an open source license license.
Especially relevant nowadays given the trend to convert previously OS repos to non-OS licenses as a business model (eg Akka or Terraform.)
TBH I use whatever build tool is the better fit for the job, be it Gradle, SBT or Rebar.
But for some (presumably subjective) reason, I like GNU Make quite a lot. And whenever I get the chance I use it - esp since it's somehow ubiquitous nowadays w/ all the Linux containers/VMs everywhere and Homebrew on Mac machines.