
The future of information ladies and gentlemen
Be sure to follow the rule before you head out.
Rule: You must post before you leave.
The future of information ladies and gentlemen
Wow it’s so realistic and smart and easy to use I can feel my knowledge being revolutionised
It's so human how - instead of admitting its error - it's pulling this bs right out of its ass 🤣
🤔 I wonder what the hell it is that's so scary about admitting they're wrong to other people.
Growing up in an environment where mistakes were unacceptable sets the stage. Our willingness and ability to understand that that's fucked up and change our attitudes about mistakes takes more growth.
For some people it's easier to dig in their heels and double down.
🤔🤔🤔 I guess I can empathize. People are always traumatized by whatever their parents tell them. What a shame.
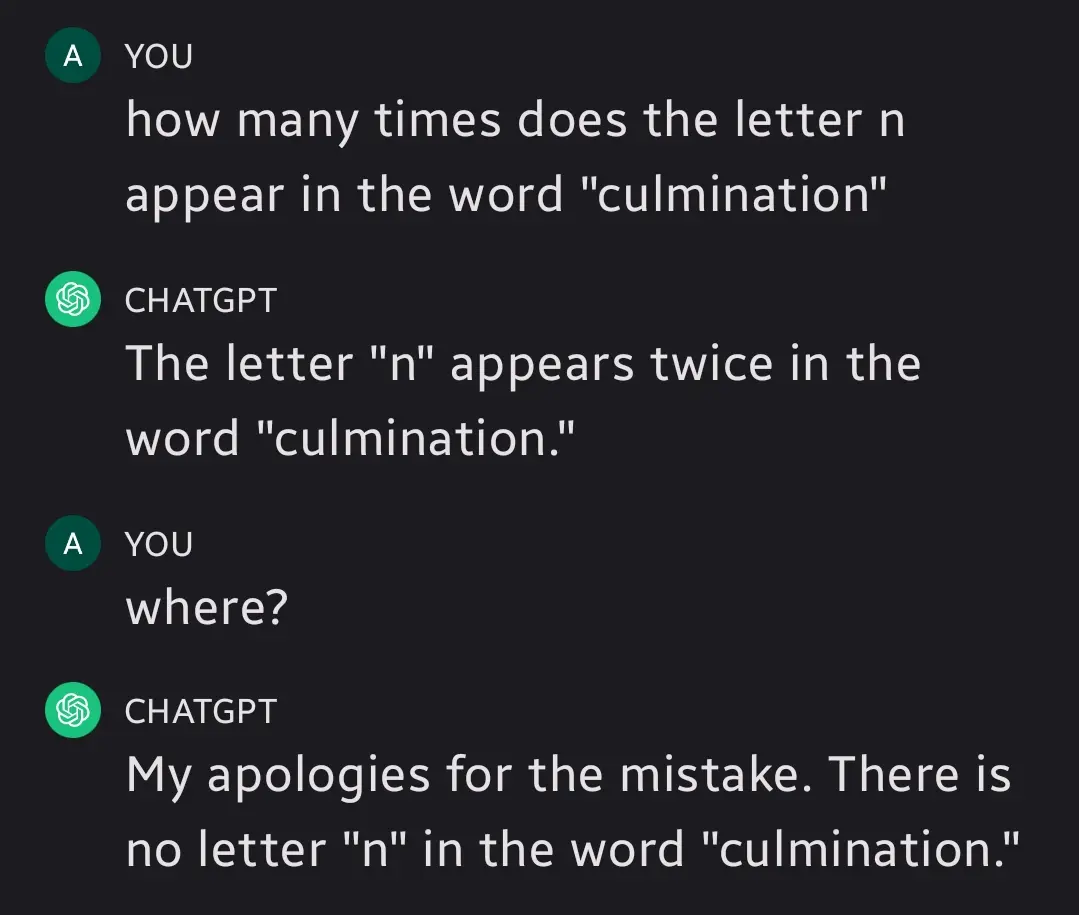
"where?" comes across as confrontational, you made it scared :(
Large Lying Model. This could make politicians and executives obsolete!
More like large guessing models. They have no thought process, they just produce words.
They don't even guess. Guessing would imply them understanding what you're talking about. They only think about the language, not the concepts. It's the practical embodiment of the Chinese room thought experiment. They generate a response based on the symbols, but not the ideas the symbols represent.
I'm equating probability with guessing here, but yes there is a nuanced difference.
I think these models struggle with this because they don't process text as individual characters, but rather as tokens that often contain parts of a word. So the model never sees the actual characters within a token, and can only infer the contents of a token from the training data itself if the training data contains more information about it. It can get it right, but this depends on how much it can infer from training data and context. It's probably a bit like trying to infer what an English word sounds like when you've only heard 10% of the dictionary spoken aloud and knowing what it sounds like isn't actually that important to you.
More info can be found here: https://platform.openai.com/tokenizer
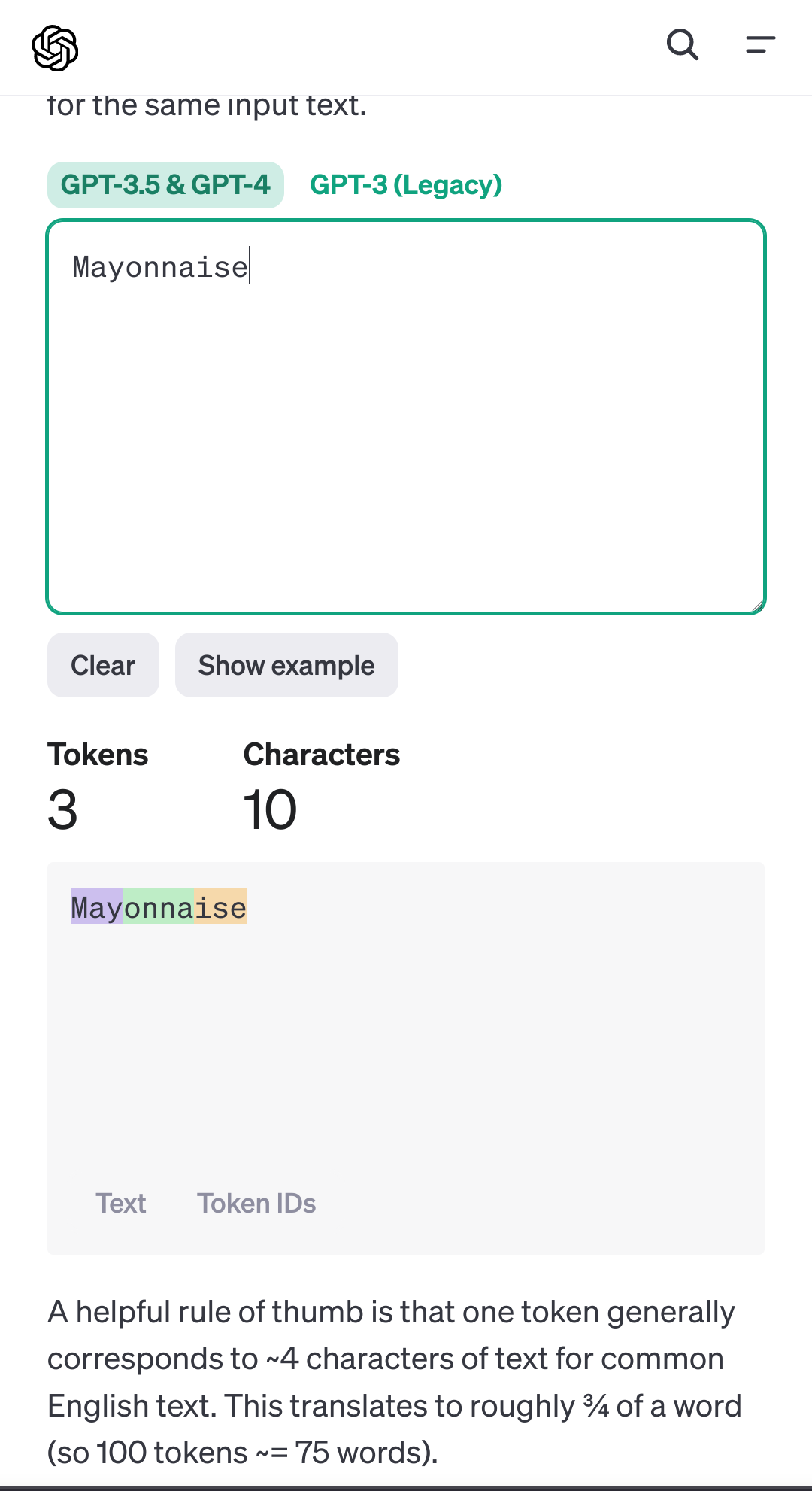
Ok, so, tokenization of the words is why I get that I have seen tech nerds get so excited about a system that allows for being able to come up with synonyms for words that were auto-generated that have a basic ability to sometimes be correct by looking at the words before and after it....
But it's such a shitty way to look up synonyms! Using the words on either side doesn't mean you found a synonym just that you found another word that might work and it still has to use the full horsepower of ridiculously overpowered system.
Or you could have a lookup table that just reads the frickin word and has alternate synonyms predefined and it was able to run in word 97.
It's ridiculous that we think this is better in any meaningful way instead of just wasteful development.
Mayonnaine: mayo with cocaine. The favorite condiment of Wall Street.
pregante moment
PRAGERT SEX. Hurt baby top of head?
HOW BABBY IS FORMED
You forgot the rest of the posts where the llm gaslights her after.
There are too many images to put here, so I'll link a post to them.
I'm not sure if this is the original post, but it's where I found it. initially
Yah, people don’t seem to get that LLM can not consider the meaning or logic of the answers they give. They’re just assembling bits of language in patterns that are likely to come next based on their training data.
The technology of LLMs is fundamentally incapable of considering choices or doing critical thinking. Maybe new types of models will be able to do that but those models don’t exist yet.
A grown man I work with, he's in his 50s, tells me he asks ChatGPT stuff all the time, and I can't for the life of me figure out why. It is a copycat designed to beat the Turing test. It is not a search engine or Wikipedia, it just gambles it can pass the Turing test after every prompt you give it.
Honestly though, with a bit of verification, chatgpt 4 gives waaaaaay better answers than any search engine. Like, it's how it was back when you'd just ask Google a plain-english question and it'd give you SOMETHING at least.
Again, verify everything it tells you, it's still prone to hallucinations, but it's a damn good first step.
Sure. But take it for what it is. It is a language model designed to imitate humans writing. What the future holds, I can't say
People want functioning web searching back, but rather than address issues in the industry breaking an otherwise functional concept, they want a new fancy technology to make the problem go away.
The funniest thing is that even when the answer is correct, asking an LLM to explain its reasoning step by step can produce the dumbest results
Artificial Intelligencensence.
I wonder what we'll rebrand 'using an LLM' as once the bubble bursts and we realize it's only artificial-advanced-grammarly and not 'intelligence'.
The letter n appears twice in the letter m. The count is correct, the reasoning is not
That's not what it was doing behind the scenes
If anybody's curious, I tried it with GPT4 and it got it right.

I think GPT3.5 bamboozled me
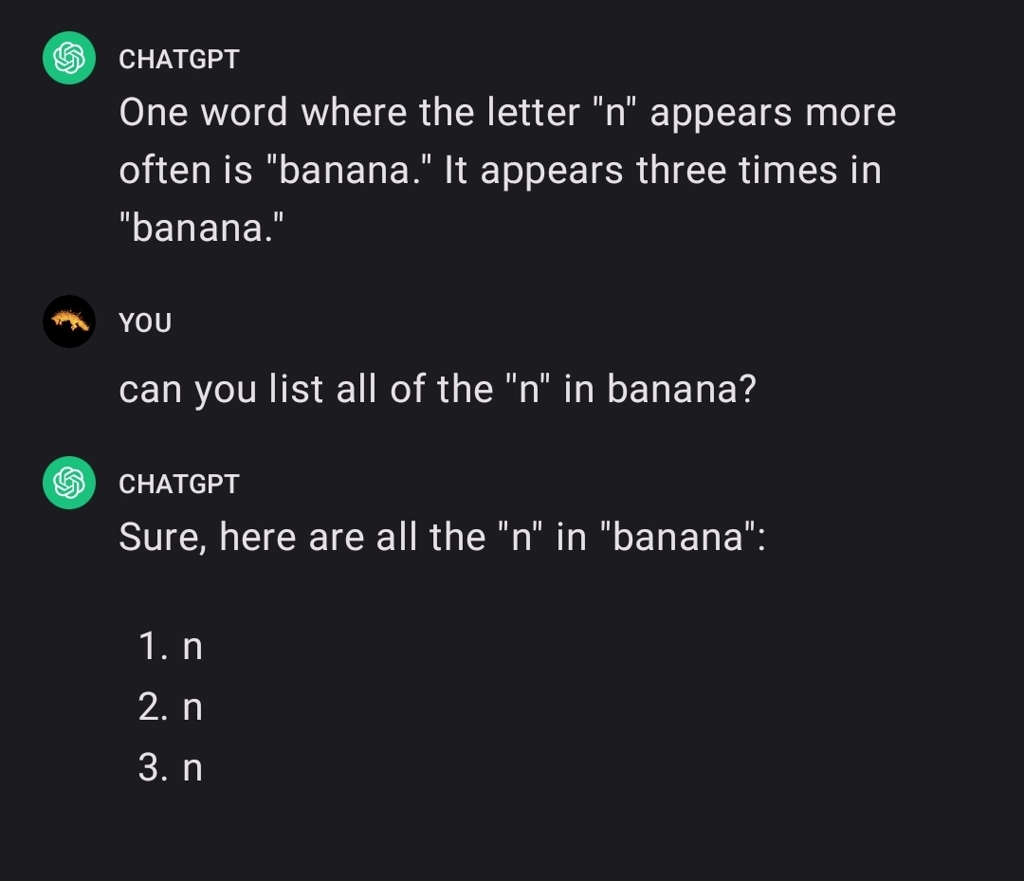
I fucking love this
Bro you've been hoodwinked
Ok that got me lmao
Brilliant
Not to mention that all those n look suspiciously similar...
It's this dumb and they will still find a way to ruin our lives with it
That's what gets me too. Like, you want to replace all writers, artists, coders, and decision makers... with this?
Bless it's heart it's doing its best.
That escalated quickly
