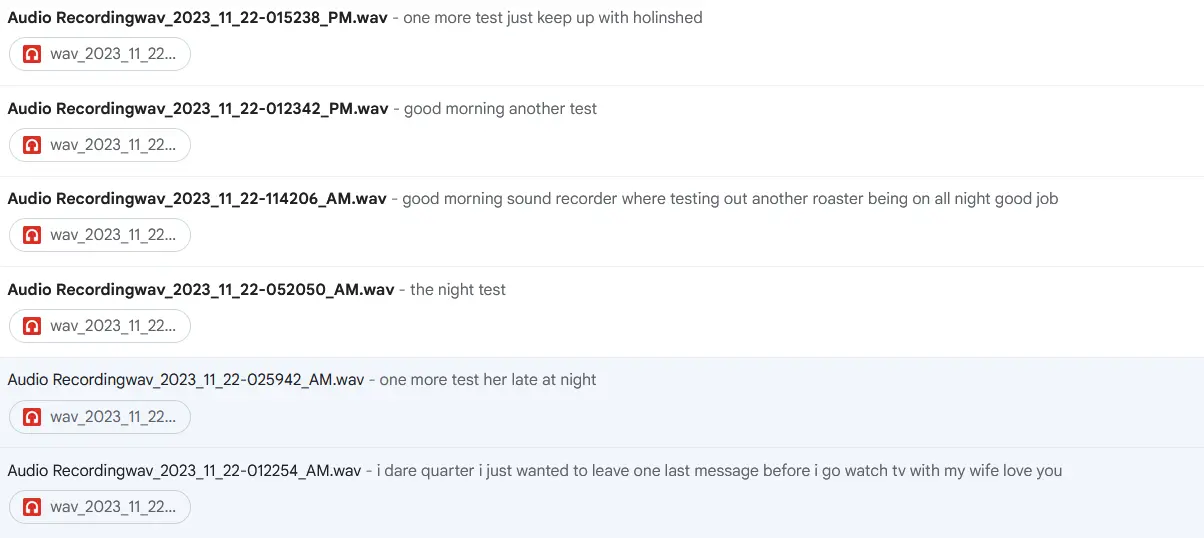
So I was finally able to get back to work on the sound recorder. The general gist is that this is meant to be an audio recorder with transcription and email capabilities, which is also ruthlessly simple to use. There's one button. You push it, a recording says "recording" and it starts recording. You push the button again and it stops recording and says "stop". It now runs the audio file through a speech recognition program, and then creates and sends an email with the transcription in the body and the wav file as an attachment. Relatives can figure out what to do with the content from there.
Progress so far:
I'd planned to follow step 3 of the Pi Spy tutorial but found that DeepSpeech was no longer supported(?) and hadn't really been made with anything less than a Pi4 in mind (I'm using a 3b). Luckily, a bunch of other speech recognition options are available, and I settled on spchcat mostly because it was the first one I found that fit my use case.
If you're going to install it on a raspberry pi, I very much recommend their issues page for getting through dependency hell. Especially if you put a 64bit OS on your pi. (Remember to get the :armhf version of whatever library it needs.) Pulseaudio also seems to help.
This is a pretty short post, I mostly just wanted to make my updated code available. It's... not great. I'm not a programmer by trade, and I'm a strong believer in 'finished not perfect' even when I know what I'm doing. It seems to be functional, that's about all I can promise. Maybe don't let anyone shout bash commands around it. There's also still no error catching around the length of the recording, or the transcription, though that at least doesn't seem to cause any issues when it fails.
This is definitely more of a jumping off point than a proper finished product, but hopefully it'll be useful to someone who's trying to make the same thing or something similar. Even if it's not perfect, maybe it'll save you from repeating some of the work I've done so far.
We're going to do another trial run, see what her feedback is, and update from there.
The updated code is here: https://mega.nz/file/LQlz1BjQ#3R6E9_k1jfmjzFUcBXq_Qi3IGf46iuYtZ95fQlAO-HI