rufus
GDPR for Dummies. GDPR is DSGVO in German, "Datenschutz-Grundverordnung".
I think what you mean is compound words vs other words?
Wikipedia says there are lots of compound words in English.
Plaintiff is borrowed from Old French. Litigation from Latin...
I suppose it boils down to when and under what circumstances a term was needed to describe something. Sometimes there was a word from another language available. Or the whole subject came from a different culture. And sometimes they just described it with a compound of what it resembles. And how to make up terms probably also depends on what is en vogue at the time.

My summary is oversimplified. I still think it's the correct answer to OP's question: is there physical evidence. Because there isn't anything physical. But there are written records from a bit later, suggesting that somebody with that name must have existed. Glad someone else thinks I picked the correct article. Seems it's not that easy to find good information. The English speaking internet is filled with low quality efforts to portray the facts in a way they'd like to have them.
I have a few good books though. Back when I was young (and became an atheist,) I used to read a lot about philosophy, the political message of the New Testament. And what life was like in that time.
Agree. But that specific article seems pretty alright. Also talks about the relics and history records for example by Tacitus.
There also is a Wikipedia article which I think is not written that well. And a lot of education material by churches or religious organizations which I did not cite for obvious reasons.
(And the German Wikipedia article about sources for the historicity of Jesus seems very good. But it's not exactly OP's question and I don't know if it helps: https://de.wikipedia.org/wiki/Au%C3%9Ferchristliche_antike_Quellen_zu_Jesus_von_Nazaret )
https://www.history.com/news/was-jesus-real-historical-evidence
Tl;dr: No.
My opinion: It's a nice story. And with stories the most important thing is what it teaches us or makes us feel. Not that it's true. Maybe they took inspiration from several preaching hippies who lived back then and made one story out of that. Exaggerated everything and made stuff up. Probably all of it because the bible was't even written close to his supposed lifetime. It'd be like you now writing a story about a dude who died in ~~1870~~. Without any previous records to get information from. [Edit: The first things have probably been written down like 40-50 years after his death.]
And I mean if Jesus existed, he would certainly disapprove of what people do (and did) in his name.
American values aren't important to them. They want different things. A strong leader, be heard, simple truths and/or some people below them to hate and pick on.
Yeah, Back when I was a kid we used to roam those point and click adventures a lot. We'd get stuck all the times. Sometimes a friend would have an idea and we'd make some progress. But the internet was slow and we still had dialup. I guess there weren't that much walkthroughs available. At least not in the parts of the internet I knew my way around... Yeah, and English is my second language. So information was kinda scarce antways, before I learned the main language of the internet in school... Everything developed and now I have everything available. I even have those old games sitting on an SD card on a Raspberry Pi and waiting for me. I really should finish that game at some point. On the flipside, I'm an adult now and it's difficult to find the time to play point and click adventures all day long 😆
And regarding the items: I tried ManiacMansion, which I believe is included in DOTT. That's properly impossible without an expert at your side.
It's a hashtag. Pretty much invisible but I can still see it.
Well that shouldn't happen. I guess it's technically possible because I can also change my own comments and they're not signed or anything... But changing other people's comments is kind if lying and being disingenuous. Either it's a technical issue, or your comment was so offensive that it warranted an exception to the rule, or the mods/admins don't know what is right and what is wrong.
They are referencing this paper: LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset from September 30.
The paper itself provides some insight on how people use LLMs and the distribution of the different use-cases.
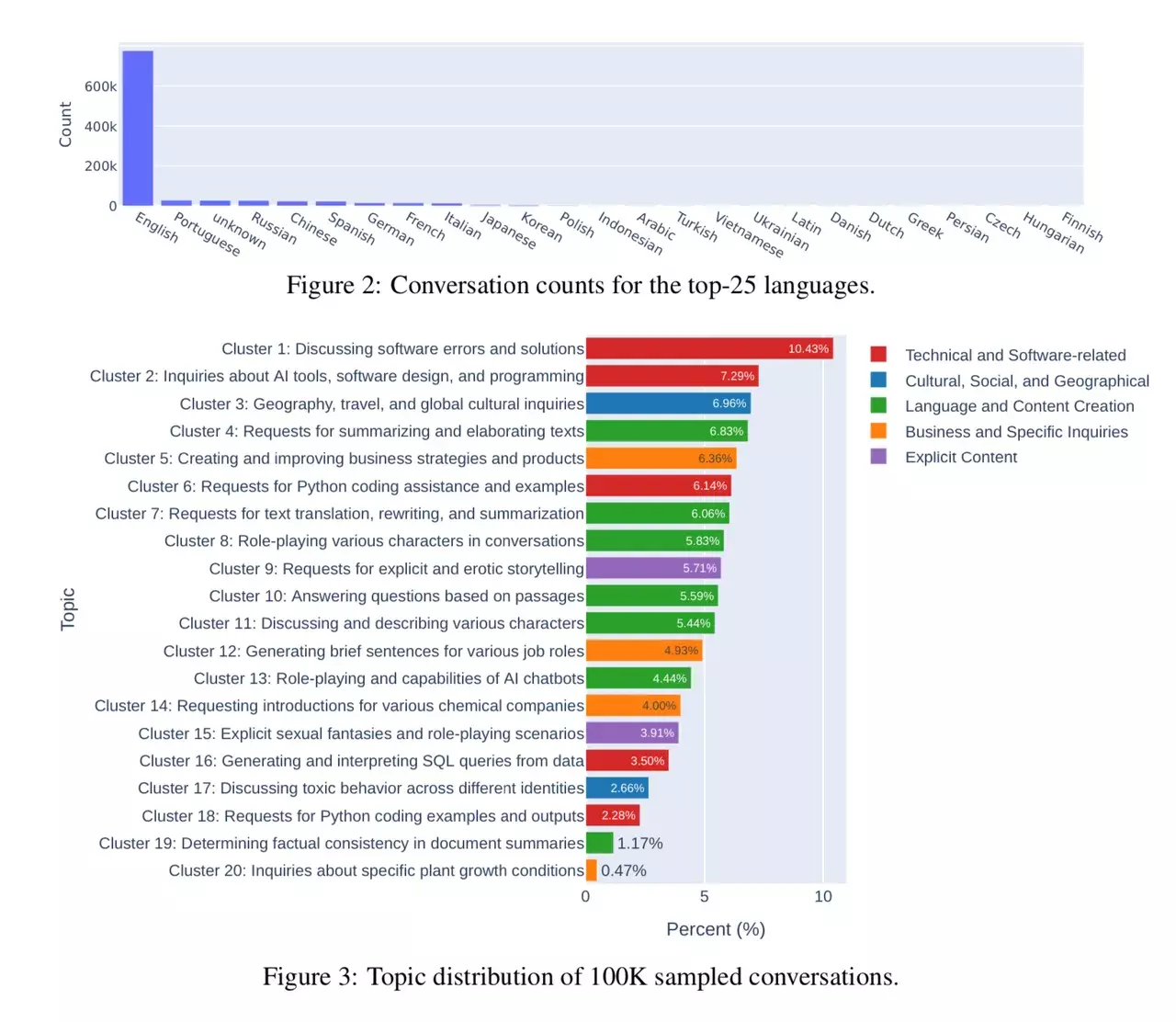
The researchers had a look at conversations with 25 LLMs. Data is collected from 210K unique IP addresses in the wild on their Vicuna demo and Chatbot Arena website.
If you're interested in finding out, why don't you buy one and try for yourself? They're not that expensive (at least the non-electronic ones)... I hear some people like it. And I mean if you're not fond of the current situation, you should switch up things and try something different anyways.
(Edit: I'd get a cheap one, see if I like it and the either throw it in the trash or have learned something and then decide if I want some $250 device with all the bells and whistles and buttplug.io integration. But YMMV on that.)