.txt or plain text files without extension are supported.
Nies221
joined 1 year ago
instructions reference INSTALL.sh but that’s not in the source? Maybe only in the release tarball?
I added it to the repository: https://github.com/Nyre221/dolphin-quick-view/tree/main/package%20creation
does it clear the user’s entire clipboard history each time it’s run?
I made some changes and now it doesn't delete all the history, only the last thing copied (afterwards try to restore it but it doesn't work if you copied a folder or file): https://github.com/Nyre221/dolphin-quick-view/blob/main/package%20creation/quick_view_package/dolphin_quick_view_shortcut.sh
this is caused by dolphin's limitations and there's not much I can do about it.
would it make sense to package this up for PyPI, with system deps being checked for and reported from within python? If so, are you interested in pull requests?
I don't think it makes much sense for this application.
For now I'm trying to integrate the modules inside a .pyz and eliminate the use of pip: https://github.com/Nyre221/dolphin-quick-view/issues/10
Thanks!
I wonder how an implementation with KPart/C++ would look like
I'm not sure what you mean, I have no experience with c++.
Look, I've never used Apple's quick look or Gnome sushi so I can't answer this question. The people here can definitely give you a better answer than me haha
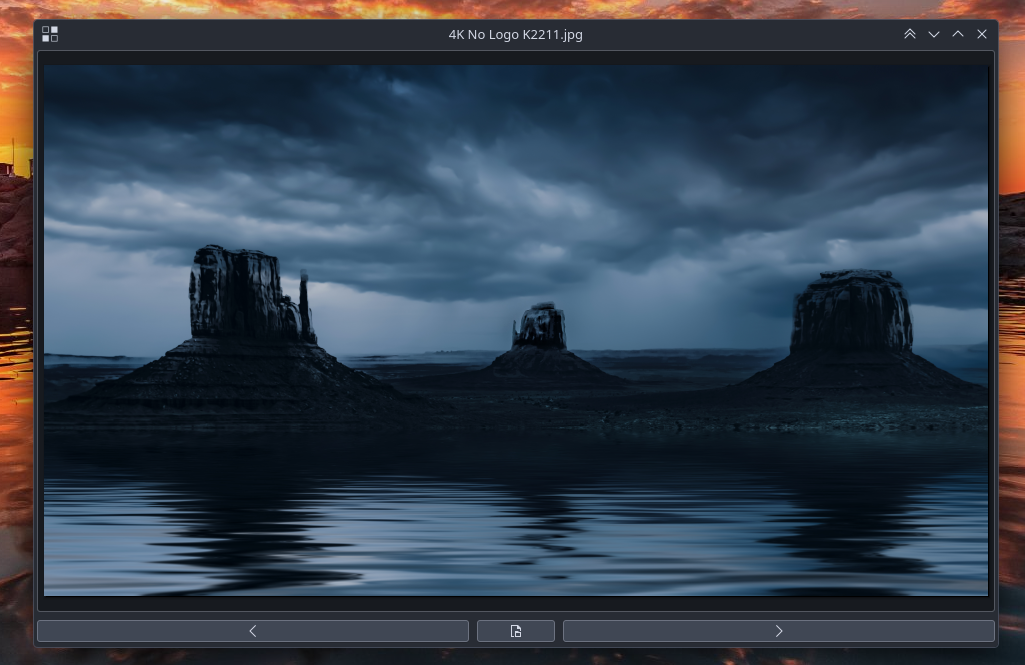
After reading about a user who was looking for an alternative to Apple's Quick Look and Sushi Gnome I decided to create this program to practice with python and make someone happy. I didn't expect there were so many people with the same need.
It looks absolutely great and I will download it, but I have a question, what advantage does it have, for example, to use this instead, for example, to open Okular to view a PDF?
I think its usefulness lies in the ability to scroll between files (even of different types) with the arrow keys, plus being fast.
It is a very simple program that allows you to have a quick overview of the contents of some files.
The program requires some python libraries and I have made a list of those needed for some distributions. they are generally always the same, just the names change a little.
Video: https://www.youtube.com/watch?v=AB1SRV1ldnw
Github: https://github.com/Nyre221/dolphin-quick-view
Download: https://www.pling.com/p/2083711/
Still better than the official reddit app.
That’s what makes it better than reddit. It can’t so easily be controlled by just a few people, because if one community/magazine on one instance gets overrun with toxicity, you can start a mag/comm with the same name on another instance.
absolutely, I am not against this kind of decentralization.
What I meant is that something could be done to collect the communities posts under one collection to make it easier for the user to join/see the communities content.
For example, if you subscribe to c/Technology you are subscribed to all the c/Technology communities (optional) in the federation. But this brings with it the problem of duplicates and I don't think there is an easy way to avoid it, and obviously different communities may have different rules.
Put simply: being able to subscribe to collections.
I say this because it seemed to me, at least initially, that for new users this presence of multiple communities with the same name was annoying and confusing.
Some time ago there was Zeronet (abandoned) that worked like this. The problem was that the speed of the site depends on how many users share the data and for heavy things like videos it was a catastrophe. On zeronet there was even a social network similar to facebook/twitter called ZeroMe: https://zeronet.io/docs/it/img/zerome.png
{kind=link}
It was a really cool project, it's a shame it's not being developed anymore.
watching the Fediverse explode while various corporate entities implode is just popcorn entertainment.
Agree
To be honest I’m still skeptical of the Fediverse
The first time I heard about the fediverse I thought it was something different, I thought it was decentralized in the sense that users act as servers in a torrent-like system. This federation thing seemed strange to me at first but I think it's still better than the usual platform controlled by a few people.
The only thing I see problematic to integrate into a reddit-like site is the presence of multiple communities with the same name belonging to different instances. Right now this is probably not helping lemmy's image.
Check that your instance is correct (lemmy.world) and try again when the server works better. Right now the server seems to be having a lot of trouble loading pages, etc, and maybe that's why it's not working for you.
I'm using liftoff:https://play.google.com/store/apps/details?id=com.liftoffapp.liftoff&pli=1
Apk of liftoff if the google play won't let you install the app: https://github.com/liftoff-app/liftoff/releases/tag/v0.10.1
others: https://lemmy.world/post/465785 and https://lemmy.world/post/401441
I hope more communities move to lemmy, especially the mental health/support ones.
As for lemmy in general, I have to say that apart from the lack of videos, it's not bad at all, even the android apps are already better than the official reddit one (terribly slow for some reason).
view more: next ›
To get the size of archives and folders:
os.stat(filename).st_size# for folders you have to use it together with os.walk()To get the list of files inside an archive I use the zipfile, rarfile and tarfile modules.
For the file type, I either extract the extension from the name or I use a bash command via subprocess:
file --mime-type filepathsubprocess is used if there is no extension (as often happens with text files).
I preferred to use subprocess to avoid having to increase the number of dependencies needed.