Hello there,
First of all; I am sorry if I am using the wrong community - and sorry for any n00bshow regarding this post since I have not done this before.
Background: To my utter delight, I found a podcast on archive.org that I have been searching for. I have succesfully downloaded all audio files listed under "VBR MP3 FILES" as a .zip file (and as a torrent), and they will download as .mp3-files. I am on Windows 10 (sorry, I will change) and using Firefox as browser.
Very long story short, a lot of files had parse errors in an ID3 editor (Mp3tag), and I incidently found out that most of the files actually seem to be .m4a-files instead of .mp3.
Nonetheless, all URLs on the podcast's main page show as .mp3-files and will download so if downloaded as a .zip or through torrent. (Or if using Edge, apparantly, which I just tested).
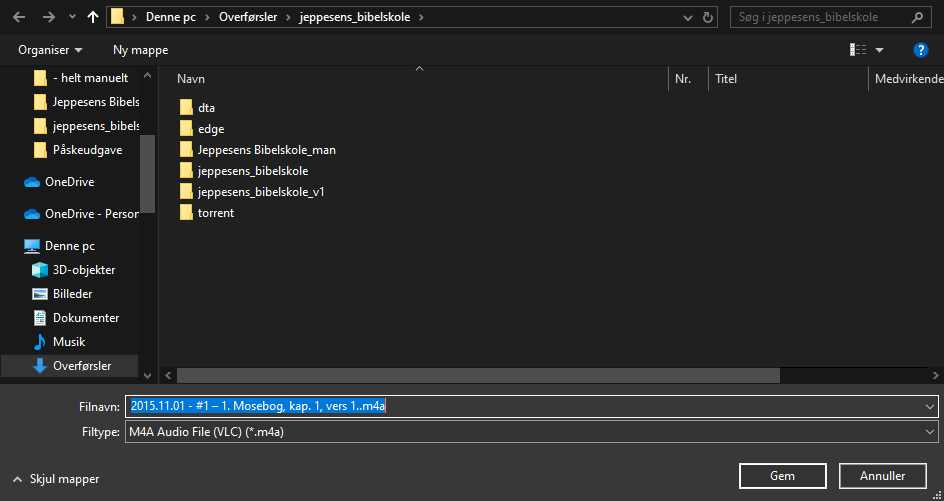
Issue: What is REALLY weird (at least to me) is that if I am right clicking a single link to an episode in Firefox > save link as > my dialog box shows it will save as .m4a-file - which seems to be the correct file type (with no parse errors in Mp3tag) which I naturally would prefer. Screenshot attached.
If been trying to search for an answer my self what is happening, but evidently failed to do so. Does anyone have an answer? And for a bonus; is it possible to batch "save link as"? wget on a Linux machine? downthemall on FF likewise download files as .mp3.
To hopefully reproduce:
- Downloading first episode "2015.11.01 - #1 – 1. Mosebog, kap. 1, vers 1..mp3" for instance as torrent
- Download the same episode by manually browsing the episodes with Firefox > click "VBR MP3" under "download options" > right click “2015.11.01 - #1 – 1. Mosebog, kap. 1, vers 1…mp3” > save link as... > it will hopefully download as .m4a.
THANK you very much in advance! Have a good one.
 While edge incorrectly tries to save the image as a jpg image:
While edge incorrectly tries to save the image as a jpg image:


